

Seu sistema de microsserviços está no ar. Dezenas de serviços em Go conversam entre si via mensageria e APIs. Tudo parece funcionar… até que a latência dispara sem aviso. O cliente reclamou primeiro. Você abriu os logs – centenas de linhas por segundo, mas nada aponta a causa raiz.
Bem-vindo ao inferno da caixa-preta. Em sistemas complexos, logs isolados não bastam. Você precisa enxergar o sistema como um todo.
É aí que entra a observabilidade – um conceito que vai além do log tradicional e se apoia em três pilares: métricas, logs e tracing distribuído. E Go, com seu ecossistema maduro e sua performance, é a ferramenta ideal para construí-la.
Neste post, vamos mostrar como implementar observabilidade real em aplicações Go, usando ferramentas do mercado (Prometheus, OpenTelemetry, Jaeger) e boas práticas que a Jacobus Software aplica em seus projetos de alta performance.
Por que logs sozinhos não salvam
Logs são ótimos para saber o que aconteceu em um ponto específico. Mas quando o problema envolve 5 serviços diferentes, 3 bancos de dados e 2 filas, você precisa responder a perguntas como:
- Qual serviço está lento?
- A lentidão começou antes ou depois do pico de tráfego?
- Qual requisição específica causou o efeito dominó?
Logs isolados não conectam essas pontas. A solução é a observabilidade – a capacidade de entender o estado interno de um sistema apenas olhando seus dados externos (métricas, traces, logs).
Os três pilares da observabilidade em Go
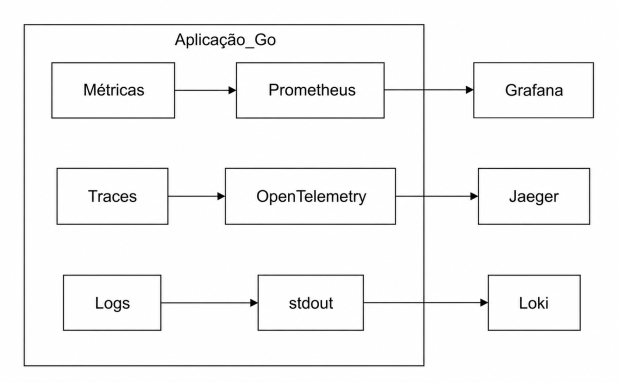
1. Métricas: o que está acontecendo?
Métricas são dados numéricos agregados (contadores, histogramas, gauges). Elas respondem a quantas requisições por segundo, qual a latência média, quantos erros 500.
Em Go, com Prometheus:
import "github.com/prometheus/client_golang/prometheus"
var (
httpRequestsTotal = prometheus.NewCounterVec(
prometheus.CounterOpts{
Name: "http_requests_total",
Help: "Total de requisições HTTP",
},
[]string{"method", "status"},
)
httpRequestDuration = prometheus.NewHistogramVec(
prometheus.HistogramOpts{
Name: "http_request_duration_seconds",
Help: "Duração das requisições HTTP",
Buckets: prometheus.DefBuckets,
},
[]string{"method"},
)
)
func init() {
prometheus.MustRegister(httpRequestsTotal, httpRequestDuration)
}Exponha o endpoint /metrics e configure o Prometheus para coletar. Em minutos, você já tem dashboards no Grafana.
2. Tracing distribuído: onde exatamente está o problema?
Tracing rastreia uma única requisição através de todos os serviços e componentes. Cada etapa vira um span (ex: “API gateway recebeu”, “serviço de pedidos consultou banco”, “serviço de pagamento chamou provedor externo”).
Em Go, com OpenTelemetry + Jaeger:
import (
"go.opentelemetry.io/otel"
"go.opentelemetry.io/otel/attribute"
)
func handler(w http.ResponseWriter, r *http.Request) {
tracer := otel.Tracer("meu-servico")
ctx, span := tracer.Start(r.Context(), "processa-pedido")
defer span.End()
// passo 1: consulta banco
span.AddEvent("consultando banco")
// ... consulta
// passo 2: chama serviço externo
span.SetAttributes(attribute.String("pedido.id", pedidoID))
// ... chama
}Com Jaeger rodando, você vê uma visualização de cada requisição – onde demorou, onde falhou, o que é gargalo.
3. Logs estruturados: o contexto que faltava
Logs devem ser estruturados (JSON) e enriquecidos com trace IDs – assim você pode correlacionar logs com traces.
Go 1.21+ vem com slog nativo:
import "log/slog"
logger := slog.New(slog.NewJSONHandler(os.Stdout, nil))
// log com contexto
logger.Info("pedido criado",
"pedido_id", pedidoID,
"cliente_id", clienteID,
"trace_id", traceID,
)Com um simples grep por trace_id, você encontra todos os logs daquela requisição específica, mesmo que ela tenha passado por 10 serviços.
Exemplo prático: Rastreando uma saga de e-commerce
Imagine seu sistema de pedidos publica um evento PedidoCriado. O serviço de estoque consome e reserva produtos. O de pagamento processa.
Sem observabilidade: Atraso de 2 segundos. Você suspeita do estoque? Do pagamento? Do kafka? Fica cego.
Com observabilidade:
- Uma métrica no grafana mostra que a latência do serviço de estoque disparou às 14h32.
- O trace mostra que a query SQL que reserva estoque levou 1,8s (antes era 50ms).
- O log estruturado do estoque mostra um
lock_timeoutpor conta de uma transação concorrente.
Em 5 minutos, você achou a causa. E corrigiu.
Como a Jacobus implementa observabilidade em Go
Nos projetos da Jacobus, adotamos uma stack padrão:
| Pilar | Ferramenta | Nível de integração |
|---|---|---|
| Métricas | Prometheus + Grafana | Exposição de métricas customizadas em cada serviço |
| Tracing | OpenTelemetry + Jaeger | Auto-instrumentação de HTTP/gRPC e manual em pontos críticos |
| Logs | slog (JSON) + Loki | Todos os logs em JSON, com trace_id, span_id e service_name |
Além disso, aplicamos geração de trace IDs no primeiro ponto de entrada (API gateway) e propagamos via cabeçalho traceparent (padrão W3C) em todas as chamadas – garantindo correlação total.
Resultado: clientes Jacobus raramente perdem mais do que minutos para identificar a causa raiz de problemas em produção.
Conclusão: pare de fingir que logs são suficientes
Se seu sistema tem mais de três serviços, você precisa de observabilidade. Métricas, traces e logs estruturados transformam sua caixa-preta em um cockpit transparente. Go, com seu ecossistema de bibliotecas e sua simplicidade, torna a implementação direta e eficiente.
Na Jacobus Software, não entregamos apenas código. Entregamos a capacidade de enxergar o que esse código faz – para que sua equipe durma tranquila e seus clientes não sejam surpreendidos por problemas invisíveis.
🔍 Quer enxergar dentro do seu sistema?
Nossos especialistas implementam observabilidade completa em Go, com dashboards, alertas e tracing que transformam sua operação.